The end of the router - Hannes Gredler

I can still remember my first encounter with a router. It was in 1993 when I was a freshman in college and the network administrator received its brand new Cisco MGS and connection to the Austrian Academic Network (ACONet AS1853) using a 64KBit/s leased line. There it was, the magical piece of technology that allowed one to telnet and ftp to retrieve information from every corner of the planet.

Since then, routers have made great advances. Its forwarding planes have matured from single CPU, to multi CPU, to dedicated IP lookup chips, to fabrics of dedicated IP lookup chips. For the past two decades, networking kit vendors have had a difficult time keeping pace with the rapid adoption of Internet services and demand for bandwidth hungry applications. Service Providers struggled to monetize on their investment in their network, and asked Networking kit vendors to help them build value added services. A wide variety of Layer-2/Layer-3 Services around MPLS has emerged since then. All of those features are part of most every router offering to Internet Service Providers.
Critics of router-based network services argue, that it’s adding and never removing features, keeps driving up the cost of the routers to a point where advances of Moore’s law are not passed down to customers any longer. James Hamilton (VP and Distinguished Engineer @ Amazon Web Services) expressed that observation. “The network is Anti-Moore” on AWS re:invent 2014, a convention for Amazon customers (Advance to 07:10' to “Get Networks out of the way”). There is some truth to it, so lets explore the various dimensions of “Bloat”, that finally have turned Networking gear, “Anti-Moore”.
Hardware Buffer Bloat
Having grown up in the 64KBit/s era, I have learned that routers must have sufficient buffers. Depending on whom you talk to, the term “sufficient” varies widely. In an epic 2004 paper from Stanford University “Sizing Router Buffers”, researchers have observed that Buffers, as deep as 2000ms, clearly have served well for low bandwidth services and flow diversity of order of hundreds like in the days of the Internet. However with Speeds of 10GBits/s and flow diversity of 10Million flows, on a typical Internet backbone link, the value of buffering and its lack of signal to TCP becomes highly doubtful. Yet, most routers still support a 100ms+ buffer depth for 100GB/s circuits. Just do the math: (100 Gigabit/s * 100 ms = 10 Gigabit = 1.25 Gigabyte). In other words: you need 1.25 GB DDR4 RAM for each 100GB/s port in a given router.
So, you have the most expensive class of memory for a function (congestion detection) that rarely works on Internet backbone traffic patterns. The worst thing about “buffer bloat”, is that it is the single, biggest driver, for hardware costs as this memory needs to be implemented as off-chip memory, which again drives up costs for external I/O, power footprint and cooling.
Hardware Forwarding Table Bloat
The next biggest cost factor for a router’s data plane, is the size of its forwarding table. Contemporary hardware can store approximately the equivalent of 2 million forwarding entries in its IPv4, IPV6, and MPLS forwarding tables. The design of those forwarding engines has been driven by two thoughts:
• A single forwarding entry can consume a large amount of traffic. A single prefix may even consume the entire bandwidth of a link. Today, this continues to be a true assumption, as Content Delivery Networks, and Web 2.0 companies, attract a large part of Internet traffic to only a few IP prefixes.
• All forwarding entries may carry the full link bandwidth. This is clearly invalid today. Like all “organic” systems, the Internet shows an exponential distribution for its “traffic-per-prefix” curve. At Nanog64, Brian Field, has analyzed Comcast backbone traffic patterns and came to the following traffic-per-prefix distribution:
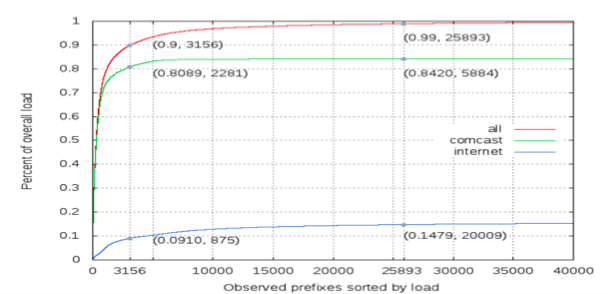
The Table suggests that Packet forwarding chips should be designed radically different. Rather than treating every IP forwarding entry equal, imagine building a Memory Cache hierarchy comparable to contemporary Computer designs: a tiered memory hierarchy with Level-1, Level-2, and Level-3 memory, at varying speeds and cost. To illustrate how cost-ineffective contemporary router data planes are, imagine how much a laptop would cost if its entire main memory would be bolted on the L1 CPU cache. What modern IP routers do is exactly this. Every forwarding entry has to be fast. Analysis of real backbone traffic data, says it does not have to be. For all practical purposes, today, forwarding tables are oversized by a factor of 10x today.
The good news is, that Hardware bloat is not too difficult to change. Once customers clearly do articulate what is needed then usually, the next generation of forwarding hardware can easily get downsized. Networking Software however, is a different class of problem.
Software Feature Bloat
Before coming to conclusions about what is broken in the Industries’ prevailing software delivery model, one first has to analyze how software is built, extended, and maintained over time. Assume Vendor A has a working, scalable implementation of a piece of networking software; let’s say a routing protocol. Over time, Service Provider customers, come up with all sorts of enhancement requests; some more useful than others. Usually, the enhancement request gets prototyped first, validated, and then merged back into the main line code. The fundamental problem here, is that it is not possible to de-feature certain functionality once merged. It is not possible to custom-tailor what the customer wants. There is no package manager that allows you to mix and match packages. There is no component that allows you to uninstall certain packages that you do not need. Consider the following analogy: You get in a restaurant, no menu being handed out. Long wait and next the big family-of-12 plate gets served. You really just like the salad and the chicken, but yet you have to pay for the full-plate as this is the “taste that everybody wants”. One might argue that, “its just software, and by not using it, nothing gets wasted.” But, that’s just one side of the story. Keep in mind that networking vendors need to maintain that piece of unused code foreverand there is hence, an eternal tax for integrating further features as one as to always run interference tests among all the features, including the ones that you do not need. So how does de-featuring software work?
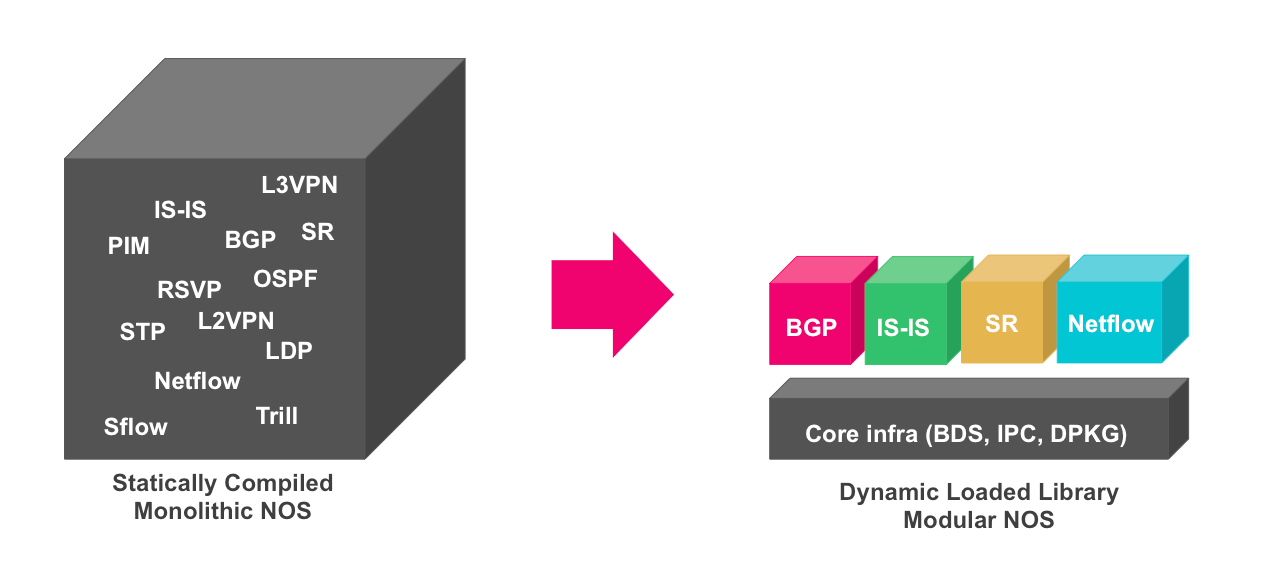
Simple answer — Not at all — At least, not today
Just ask your networking vendor for the following tailor-made software release:
· IS-IS
· BGP for IPv4 and IPv6
· no OSPF
· no LDP
· no RSVP
· no Spanning Tree
· no PPP-over-pigeons
· no nothing.
Not possible? — Reason it is not possible is because things have been constructed as a monolithic system, mostly by just compiling a new feature. Most often, a given feature is intimately linked to the underlying infrastructure (like an in-memory database, or some event queue processor), and, removing it out of the code base, may get to an effort as large as originally developing the feature. In most cases there is no dedication on how to clean things up later.
Every added feature will make future feature additions harder. If you just make the number of supported software features large enough, you can extrapolate, that at some point, this will become unmaintainable. External measure of such a condition, is too hard it is to get functionality into a particular main line release. If you are already using software which can never get “de-featured”, I have bad news — you are doomed to spend your life in the “eternal bug hell.” Availability goes down, operational cost goes up, and your vendor cannot possibly fix it. Time to change vendors is the only way out.
Lack of the ability to de-feature software can be viewed as some form of technical debt. Debt-making, until it breaks, seems to be a problem of broader applicability than just the networking industry, however lets see how this piles up.
Software Technical Debt and the unwillingness to reduce it
Wikipedia lists many possible sources of technical debt. I have mainly encountered the following five:
• Business, pressures sales teams, pushing hard for shipping the feature. Engineering teams run out of time. Nobody wants to pull out; happens all the time. This is a good problem to have. Where things gets derailed is when the technical debt (lack of testing, lack of documentation, lack of refactoring) gets piled up, and there is no commitment to a cleanup plan.
• Delayed refactoring. This is the little brother of the ‘Business pressures’ reason. All stakeholders do understand, that some infrastructure component cracks frequently under pressure, but yet nobody, is allocating budgets for rectifying the problem.
• Lack of a test suite. Hardly understandable if you consider “state of the art” Developmental and operational models like DEVOPS. That software may get rolled out without proper test coverage. Yet, there are tests frameworks from the previous century. I sometimes get the feeling, that the rationale for not improving the test tools, is that those would unveil a lot of lurking bugs, leading to further oversubscription of the already stretched engineering crew. Better to avoid going down that hole before the CxO asks nasty questions.
• Poor technological leadership, refactoring, and changing the way testing is done, requires usually an additional budget. For Engineering Managers, it takes guts to admit that something has gone wrong and have to ask for additional budget to clean it up. I have encountered many managers who fear taking that step. It’s their inertia, which makes a manageable problem an unmanageable one. A very good friend of mine once coined the term, Lord of Nothing, for managers not willing to clean up what has to get cleaned up. I can only speculate as to what drives, or does not drive them. Surrendering to fear for getting a clean-up budget approved, is clearly a sign of bad leadership.
• Lack of building loosely coupled components. A loosely coupled system, or sometimes called “micro service” architecture, is the antithesis of a monolithic code base. It basically means to construct a larger application into small components, which does a very basic thing. It is a lot like the UNIX paradigm, that allows to pipe the output of one program, as the input of another. In my opinion this is the cardinal mistake of technical debt. Lack of micro-services architecture renders technical debt possible.
Conclusion
The router, and the dynamic control-plane, as basic forwarding paradigm of the Internet, remains undisputed. However, it gets challenged using new concepts like SDN and NFV, which promise much faster network adoption, automated control, reduced time-to-revenue, which all are good business solutions. In order for router designs to be competitive to those challenges, requires to re-imagine how router hardware and software get engineered. I am proposing to fundamentally rethink the router, adopt modern software architecture and paradigms, and urge the industry to catch up after 10 years of stagnation.
About the Author
Since my first encounter with a Cisco MGS router in the networking room of my college in 1993, I have been in love with packet based forwarding and routing protocols.
Sun Microsystems’ famous quote “The network is the computer” served for more than one decade as an inspiration how to design distributed web applications. What I always have wondered is, why Hyper-scale application design patterns have never been applied to Routing and Networking.
Therefore i co-founded rtbrick.com where those Hyper-scale design principles are followed. In a nutshell we’re building the next generation distributed routing and forwarding platform with unbounded scale on your choice of open hardware.